
SafeKids 프로젝트 1: Rust와 Tesseract OCR로 실시간 화면 모니터링하기 :->
안녕하세요! 6년 차 개발자 김재준입니다 :->
지난번 SafeKids SNS 아키텍처 설계 포스팅에 이어, 드디어 첫 번째 프로토타입 개발에 착수했습니다!
원래 계획대로라면 바로 안드로이드나 iOS 모바일 앱으로 개발을 시작해야 했는데요. 막상 시작하려고 보니 꽤 큰 난관이 있었습니다. 스마트폰 환경에서 다른 앱의 화면을 읽거나 네트워크를 가로채려면 VpnService나 접근성(Accessibility) 권한이 필요한데, 이 권한들을 얻고 인증을 통과하는 과정이 초기 프로토타이핑 단계에서는 너무 무겁고 까다로운 제약으로 다가왔어요.
그래서 방향을 조금 수정했습니다. 핵심 기능인 ‘실시간 텍스트/이미지 AI 필터링’이 의도대로 잘 동작하는지 빠르게 검증하기 위해, 권한 제약에서 비교적 자유로운 PC 환경에서 먼저 테스트를 진행해 보려고 합니다.
자, 여기서 질문! PC 화면에 띄워진 SNS 화면을 실시간으로 읽어와야 하는데, 이때 화면 속 글자들을 어떻게 텍스트 데이터로 변환할 수 있을까요? 여기서 우리가 사용할 기술이 바로 Tesseract OCR입니다.
오늘은 이 Tesseract OCR이 무엇인지, 그리고 어떤 원리로 동작하는지 찰떡같이 정리해 드릴게요! :-D
1. Tesseract OCR이란 무엇인가요?
OCR(Optical Character Recognition)은 ‘광학 문자 인식’이라는 뜻으로, 쉽게 말해 이미지 속에 있는 글자를 컴퓨터가 읽을 수 있는 실제 텍스트 데이터로 변환해 주는 마법 같은 기술을 말합니다.
그중에서도 Tesseract(테서랙트)는 휴렛패커드(HP) 연구소에서 처음 개발을 시작해, 현재는 구글의 지원을 받으며 꾸준히 발전해 온 대표적인 오픈소스 OCR 엔진이에요.
파이썬(Python) 생태계와 굉장히 잘 맞물려 있어서 pytesseract 같은 라이브러리를 통해 단 몇 줄의 코드만으로도 이미지 속 글자를 추출할 수 있다는 엄청난 장점이 있습니다. 무엇보다 무료로 오프라인(온디바이스) 환경에서 동작하기 때문에, 인터넷 연결 없이 아이들의 기기 내부에서 빠르고 안전하게 텍스트를 검사해야 하는 우리 SafeKids 프로젝트의 목적과 아주 찰떡궁합이죠! :->
2. Tesseract OCR은 어떤 원리로 글자를 읽을까?
사람은 화면을 보면 직관적으로 글자와 배경을 딱! 구분하지만, 컴퓨터에게 이미지는 그저 픽셀(점)들의 색상 덩어리일 뿐입니다. 컴퓨터가 이 픽셀 덩어리에서 텍스트를 추출하기 위해서는 크게 4단계를 거치게 됩니다.
💡 참고 이미지: Tesseract OCR 원리 (출처: koreadeep 블로그)
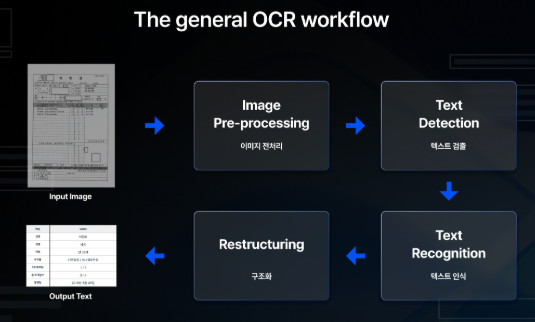
1단계: 이미지 전처리 (Image Pre-processing)
컴퓨터가 글자를 쉽게 알아볼 수 있도록 이미지를 예쁘게 다듬는 과정입니다. 가장 먼저 컬러 이미지를 흑백으로 변환하고, 글자와 배경을 극단적으로 분리하는 이진화(Binarization) 작업을 거쳐요. 이때 화면의 노이즈를 제거하고 삐뚤어진 텍스트의 기울기를 보정하는 작업도 함께 진행합니다.
2단계: 텍스트 검출 (Text Detection)
전처리가 끝난 이미지에서 ‘어디가 글자이고, 어디가 여백인지’ 텍스트가 있는 영역만 정확하게 찾아내는 과정입니다. 문단, 줄, 단어 단위로 가상의 네모난 박스(Bounding Box)를 치며 텍스트의 위치를 검출해요. PC 모니터 전체를 캡처했을 때 사진이나 아이콘은 쿨하게 무시하고 글자 영역만 골라내는 아주 중요한 단계입니다.
3단계: 텍스트 인식 (Text Recognition)
이제 찾아낸 영역 안에서 진짜 글자가 무엇인지 읽어낼 차례입니다. 여기서 아주 중요한 기술적 포인트가 하나 있어요! Tesseract 4.0 버전 이상부터는 인간의 뇌 신경망을 모방한 딥러닝 기술인 LSTM(Long Short-Term Memory) 알고리즘이 본격적으로 적용되었습니다.
과거에는 단순히 글자의 겉모양만 보고 판단했다면, 이제는 “앞에 ‘안’이라는 글자가 왔으니 뒤에는 ‘녕’이라는 글자가 올 확률이 높겠군!” 하고 문맥을 기억하며 앞뒤 글자의 패턴을 추론해요. 덕분에 한국어처럼 복잡하고 띄어쓰기가 중요한 언어에서도 꽤 훌륭한 인식률을 보여줍니다.
4단계: 구조화 (Restructuring)
마지막으로 인식된 텍스트들을 사용자가 읽기 편하도록 원래의 레이아웃이나 표 형태에 맞게 재배치하고 다듬는 과정입니다. 줄 바꿈이나 띄어쓰기 등의 서식을 맞추고 나면, 비로소 우리가 코드에서 바로 지지고 볶고 활용할 수 있는 순수한 문자열(Output Text) 데이터가 완성됩니다! :-)
3. SafeKids SNS 프로토타입에 어떻게 적용할까?
우리 프로젝트에서는 PC 화면의 특정 영역(예: 웹 브라우저 창)을 1초에 몇 번씩 연속으로 캡처한 다음, 이 이미지를 Tesseract 엔진에 던져줄 예정입니다. 과정은 대략 이렇습니다.
mss나xcap같은 라이브러리로 PC 화면을 캡처합니다.- 캡처한 이미지를 흑백으로 이진화 처리(전처리)를 합니다.
- 전처리된 이미지를 Tesseract에 넣어 텍스트를 뽑아냅니다.
- 뽑아낸 텍스트를 독성 분석 모델(또는 키워드 매칭 엔진)에 전달하여, 욕설이나 혐오 표현이 있는지 검사합니다.
4. 실시간 화면 모니터링: 핵심 알고리즘 구현 (Rust)
자, 이제 말로만 하던 걸 코드로 직접 짜볼 시간입니다. 제가 작성한 코드는 비동기 런타임인 tokio 위에서 돌아가며, 3초마다 주 모니터 화면을 캡처해서 검사하는 로직이에요.
우선 필요한 마법의 도구(크레이트)들은 다음과 같습니다.
xcap: 크로스 플랫폼 화면 캡처를 지원합니다.rusty_tesseract: 파이썬이 아닌 Rust 환경에서 Tesseract 엔진을 구동합니다.aho_corasick: 텍스트 내 유해 키워드를 빛의 속도로 매칭해 줍니다.notify_rust: 감지 시 데스크톱(OS) 자체 알림 팝업을 띄워줍니다.
아래는 SafeKids PC 프로토타입의 핵심 모니터링 코드입니다. 한 번 살펴볼까요? :-D
use aho_corasick::AhoCorasick;
use notify_rust::Notification;
use rusty_tesseract::{Args, Image};
use std::time::Duration;
use tokio::time;
use xcap::Monitor;
const BAD_WORDS: &[&str] = &["바보"];
pub async fn start_screen_monitoring() {
println!("🔍 화면 모니터링을 시작합니다...");
// Aho-Corasick 알고리즘으로 유해 단어 엔진 초기화
let ac = AhoCorasick::new(BAD_WORDS).unwrap();
let mut interval = time::interval(Duration::from_secs(3)); // 3초마다 검사 (성능 고려)
loop {
interval.tick().await;
// 주 모니터 화면 캡처
let monitors = Monitor::all().unwrap();
if let Some(primary_monitor) = monitors.first() {
match primary_monitor.capture_image() {
Ok(img) => {
// 메모리상에서 이미지를 Tesseract용으로 변환
// (실무에서는 이미지 크기 축소나 흑백 변환 등 전처리로 속도를 최적화해야 합니다!)
let dynamic_img = image::DynamicImage::from(img);
if let Ok(tesseract_img) = Image::from_dynamic_image(&dynamic_img) {
let args = Args {
lang: "kor+eng".to_string(), // 한국어, 영어 동시 인식
..Default::default()
};
// OCR 텍스트 추출
match rusty_tesseract::image_to_string(&tesseract_img, &args) {
Ok(extracted_text) => {
// 유해 단어 감지
let mut matches = vec![];
for mat in ac.find_iter(&extracted_text) {
matches.push(BAD_WORDS[mat.pattern()]);
}
if !matches.is_empty() {
println!("⚠️ 화면에서 유해 단어 감지됨: {:?}", matches);
// OS 알림 띄우기
let _ = Notification::new()
.summary("SafeKids 경고")
.body("화면에서 유해 콘텐츠가 감지되었습니다!")
.icon("dialog-warning")
.show();
}
}
Err(e) => {
eprintln!("❌ OCR 인식 실패! Tesseract가 설치되지 않았거나 경로가 잘못되었습니다: {:?}", e);
}
}
}
}
Err(e) => eprintln!("화면 캡처 실패: {:?}", e),
}
}
}
}
💡 코드 핵심 리뷰
방금 작성한 코드가 어떻게 유기적으로 맞물려 돌아가는지 단계별로 가볍게 뜯어볼게요.
1. 3초 단위의 무한 루프 캡처 (xcap & tokio::time)
실시간 필터링이라고 해서 1초에 60번씩 화면을 검사하면 컴퓨터 CPU가 비명을 지르며 터져버릴지도 모릅니다. 그래서 tokio의 interval을 사용해 3초에 한 번씩만 주 모니터의 화면을 찍도록 얌전하게 조율했습니다.
2. 메모리 단에서의 이미지 처리 (rusty_tesseract)
캡처한 이미지를 하드디스크에 저장했다가 다시 불러오면 I/O 병목 때문에 속도가 너무 느려집니다. 그래서 화면을 캡처한 즉시 메모리 상에서 바로 DynamicImage로 변환하여 Tesseract 엔진에 밀어 넣습니다. 한국어와 영어가 섞여 있는 요즘 SNS 환경을 고려해서 lang: "kor+eng" 옵션도 잊지 않고 챙겨주었어요.
3. 유해 단어 발견 시 시스템 알림 표출 (notify_rust)
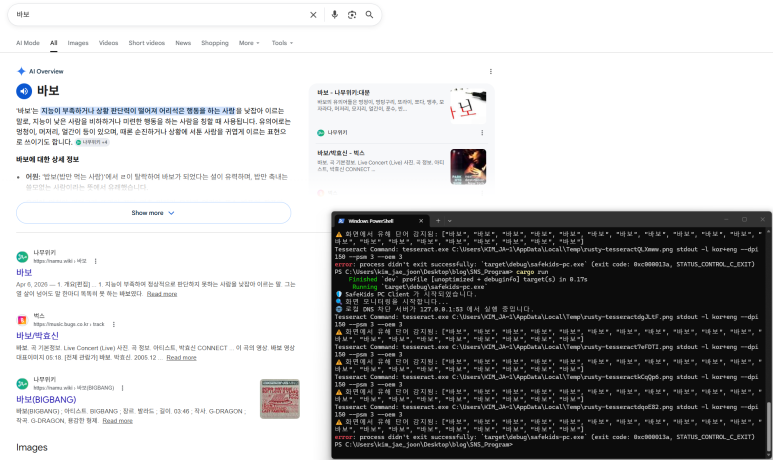
고속 문자열 매칭의 최강자인 Aho-Corasick 엔진이 추출된 텍스트에서 ‘바보’라는 단어를 찾아내면, 즉시 바탕화면 우측 하단에 “SafeKids 경고”라는 팝업을 띄워줍니다. 이 기능이 딱 동작하는 순간, 정말로 나만의 백신이나 보안 프로그램을 만든 것 같은 짜릿한 실감이 난답니다! :->
💡 테스트 결과: > 화면에 띄워진 ‘바보’의 개수만큼 인식이 되어서 배열에 담겨 출력되는 상황입니다!
마무리하며
오늘은 모바일 앱 개발의 높은 진입 장벽을 살짝 우회하기 위해 선택한 PC 프로토타입 테스트 환경과, 그 핵심 기술이 될 Tesseract OCR의 원리 및 Rust 코드 구현까지 알아보았습니다.
점점 머릿속에만 둥둥 떠다니던 아이디어가 실제 코드로, 그리고 눈에 보이는 알림 팝업으로 실현되는 느낌이라 아주 기대가 되네요. :-)
긴 글 읽어주셔서 감사합니다! 다음 포스팅에서는 이 프로토타입을 조금 더 고도화하는 재미있는 과정으로 다시 찾아뵙겠습니다. 다들 즐거운 코딩 하세요! :->
<hr>